刊行物
応募書類の受付は4月26日13時に締め切りました。
書類の受諾状況は、5月中旬頃に応募者登録サイトに表示されます。
"Application forms were closed at 13:00 on 26 April.
The acceptance status of documents will be displayed on the registration website around mid-May."
| ENGLISH |
天野 恭子
2020年度より「データ駆動型科学が解き明かす古代インド文献の時空間的特徴」と題したプロジェクトを進めている。これは、成立時期や背景が知られていない、そして詳しく知る手立てのない、古代インドのヴェーダ文献について、情報科学を援用して文献を分析し、時空間にマッピングすることを試みる学際的プロジェクトで、京大学内ファンドSPIRITS に採用され支援を受けている。筆者はヴェーダ文献(相対的なおおまかな推定で紀元前13C から5C 頃に主な部分が成立したと考えられている)の言語学的および思想・文化史的研究を専門としている。
プロジェクト応募時(2年前)、これまで例のなかった古代インド文献学と情報科学の共同研究、とアピールしたが、これは実はその時点でも少し誇張した表現であった。というのも、Digital Humanities「人文情報学」は人文学の研究において一つの異端のように見られていた段階はとうに過ぎ、すでに多くの分野に応用されており目新しいものではなくなっている。人文情報学の当初の目的は文献資料のデジタル化、アーカイブ、検索システムの構築を中心としていたかと思うが、現在の人文学研究者でその恩恵を被っていない 人はほとんどいないであろう。しかしながら人文情報学と聞いて「そういうのが好きな一部の人がやっていること」と感じる文献研究者が未だに多いのも事実。「コンピュータが文献を理解できるか!」というような反応を示す人は少なくはなってきたものの、一人の人間として文献に向き合う姿勢を大切にしてきた文献研究者は方法論の違う研究に対して議論の土台に乗りにくいとは思う。それでも、2021年2月12日にオンラインで開催した、本プロジェクトの第1回ワークショップDynamism of Social ContextDeciphered by a Linguistic Analysis of Ancient Literature「古代文献の言語分析から読み解く社会背景のダイナミズム」には、Digital Humanities に興味のある研究者だけでなく、文献学に携わる筆者の同僚たちも多く参加してくれたことはやはり嬉しかった。
さて、筆者自身は「そういうのが好きな人」では全くなく、むしろその逆で、パソコンにフォントをインストールするのも誰かに頼んでやってもらうほどのパソコン音痴。ちなみに先に文献資料のデジタル化に言及したが、筆者は2000年頃までには研究対象の文献をパソコン入力し終えていたが、それはプリントアウトしてノートを作るためのものであり、未だにそのプリントに鉛筆で書き込みをして使っている。それが何故「データ駆動型科学が解き明かす古代インド」なのか。他の人文情報学分野に関わる研究者とは少し違う入りだったと思うので、その道筋を振り返ってみたい。
そもそもサンスクリット文献の研究はスパンが長い。筆者はMaitrāyaṇī Saṁhitā(以下MS)という紀元前8C前後に作られたと考えられている宗教文献を研究対象としているが、読み始めたのは修士課程に入った1994年のこと。博士論文として全体の3分の1くらいをドイツ語訳にして提出したのが2001年。それを無事出版したのが2009年である。その間、小さいトピックをいくつか選び出して論文を書いたものの、基本的にやったことはMSを読んでいた、というそのことだけである。その後、新発見の写本を手に入れたりして多少やるべき作業が増えたものの、今でもその同じことをやっている。飽きないかと問われれば、全く飽きないと答える。一日に5行読んだとして、その5行にめちゃくちゃ多くの発見がある。こういう難しい文献なので理解しようと思うと細かく細かく情報を拾っていく。(どんどん細かくなっていくのが怖い。)AとBというほとんど同じ意味の語彙があったとして、なぜここでAを使いなぜ他の箇所ではBを使うのか。あるいは語順。サンスクリット語はフリーな語順で文を作れるので語順は文意に関係しないことが多いが、それでもなぜここでは代名詞が文頭で、そしてここでは文の2番目?なぜここで「人は」と言って他の箇所では「人々は」になっている?文の意味だけを取りたい場合には見過ごされていく細かい言語現象にも、ひっかかり続けて何年。ある時から、章によって言葉遣いが違うことを感じるようになった(MSはざっくり数えて25の章に分けられる)。これは、文法形(名詞や動詞の活用形)等の外に明らかに現れる言語の変化とは違う。そういう意味ではMSの各章は全く同じ言語で書かれている。私のいう章ごとの違いは、「言葉遣い」の微妙な違いである。例えて言うならば、分担執筆で書いた教科書。全て同じ日本語で書かれ、中身も矛盾のないように整えている。これを数千年後、日本語が失われた言語となっていて、著者の名前がわからない形で解読したとして、その言葉遣いから「何人かの人で分けて書いたのね」と気づくかどうかの話。(これよりかは違いは顕著であろうが。)
ある時まではこれを研究として発表しようと思ったことはなかった。自分としては確かなものを感じつつ、証明できないと思っていたので。風向きが変わったのは、ある研究者が、MSのある章を考察して見解を述べ、それを他の研究者がMS全体にあてはまることとして扱い、大きな発見であると喧伝し始めたことによる。一つの章から得た考察だけでMS全体の成立を論じる説が広まることに大変な危機感を覚え、MSは各章で言語的な特徴が違う、つまり各章の成立は異なる、ということを発信することにした。
自分が感じてきた章ごとの「言葉遣いの違い」をきちんと証明できるのか、が最初の問いであった。その時に、MSの各章を定量化してグラフにし、それを合わせてMS 全体を地図のように表す、そこに特徴的な言語現象をマークしていくと、章による違いが出て「層」が見えるのではと考えた。当時、計量言語学のケの字も知らなかったので、とりあえず手書き(word)で地図を作り、そこに手作業でマークを付けていった。夢中になって色々な言語現象で試したが、見事に層が見えて「ほら、やっぱり!」と膝をたたいたものだ。最初に学会で発表した時(2012年)は、他の研究者にも興奮を持って迎えられたと思う。グラフ上に層が見えるという分かりやすさに説得力があったと思う。同様の発表をいくつか続けたが、私自身この手法に手ごたえを感じつつも手作業でのマーキングの手間と扱える用例数に限界を感じ、プログラムを書ける人なら一発でグラフにして出せるのだろうと薄々感づいていたこともあり、コンピュータによるグラフ化に気持ちが傾いていった。(しかしどうしたらよいか全くわからなかった。)
きっかけというのはどこに転がっているかわからないもので、ここから先に進んだのは夫からの情報による。夫は工学部を卒業して企業に勤めているが、学部のホームカミングデーで聞いた講演が面白かったという。ビッグデータ解析を専門とする先生の話で、芸能人のSNS に投稿された情報を解析して人間関係を可視化するというもの。ネットワークマップを見ると、いくつかのグループの存在がわかり、中心的な人や関係の強さもわかる。ジャニーズは一つのグループを形成するがその真ん中に森光子がいるというのがオチだった。私のやりたいこと(ヴェーダ文献の複数の作者の関係を知りたい)に似ているのではと思って教えてくれたのだが、これはテキストマイニングとかデータマイニングとか言うもののようだった。ここからそのキーワードでリサーチを開始。これは2014年頃のことで、折しも10年間の子育てのための無職在宅期間を終え学振RPD として研究者としての肩書を再び得た頃のことだったので、この先生に会いに行って話を聞くなど精力的に動き始め、少しずつ勉強していった。そうこうするうちに白眉研究者となり、そこからますます人間関係を広げて今に至る。その詳細については、京大学術研究支援室「京都大学からはじめる研究者の歩き方」サイト https://ecr.research.kyoto-u.ac.jp/cat-b/b1/1052/ のインタビューで話したので興味を持ってくださる方はそちらを参照されたい。つまりは、学会やK-CONNEX のリトリート等で出会った研究者に積極的にアプローチ、SNS で友達の友達だった人にDM を送る、知り合いを紹介してもらって連絡する、など、少し強引だけれど貪欲に出会いを求めて、いずれも素晴らしい研究者の方々から協力を得、今に至るということである。しかしこれは武勇伝などではなく、私が構想を描き始めた頃すでに盛り上がりを見せていた言語情報学にあまりに無知であったということに過ぎないが、これは自分の分野の事情だけでなく、10 年間無職で在宅していたことが大きい。やはり大学であれ何かの研究機関であれ、何かと情報が入ってきたり人と知り合ったりする機会がないのとあるのとでは大違いだと思う。しかしともあれ現在このように活動できているので、そのような遅れはいつでも取り戻すことができるとも言える。
これまでの流れで一番大きなハードルだったのは、MSのテキストエンコーディングデータを作成するかどうかの問題であった。XMLに代表される文法解析付きのデータの作成は、日本語や英語の場合プログラムにより自動的に行うことができるが、サンスクリット語の場合はそのような自動解析プログラムは知られていなかった。サンスクリット語は単語と単語の接触で音が融合したり変化したりするため、それを原形に直す場合に複数の解釈の可能性が生じ、それを決定するのは研究者にとっても簡単なことではないからである。もし手作業で文法解析を打ち込んでいくとすれば莫大な手間がかかりやっていられない。しかし、テキストマイニング等の分析をやってみたいがどうすればいいかと自然言語処理の手法での言語分析を知る人に聞くと、百発百中で「XMLデータがないと」という答えが返ってくる。いや、だからそれ作れないんですよ、と話はいつもそこで堂々巡り。しかしリサーチをする中で、チューリヒ大学のOliver Hellwig 氏がサンスクリット語の自動解析プログラムを開発して、完全に自動とはいかないが人が訂正をいれつつデータを作成することに成功していて、いくつかのサンスクリット文献についてはすでにXMLデータを蓄積しているということがわかった。そこで「Maitrāyaṇī SaṁhitāのXML データを一緒に作りませんか」という声をかけた。Oliver にすればデータベースの充実はありがたいし、MS 研究の第一人者(私)が直々にデータを作ってくれるなら願ったり叶ったりなようだったが、彼がプログラムを開発したのはずいぶん前で、データの蓄積も一人でコツコツやってきたせいで、プログラムやデータの変換が彼のPC でしか行えないというのであった。そこで彼のシステムを他の人も使って共同研究ができるようにユーザーインターフェース仕様に作り替えるのを、私のほうで負担することにした。これはずっと一人でやってきた彼には「夢のような」話(Das wäre ein Traum!)だったようだが、自分のような者でも誰かの助けになれるのかと私も嬉しかった。
その後、このシステムを使ってMS のデータ作りが順調に進行している。このデータがあれば様々な分析を行うことができ、近い将来、私が思い描いていた文献成立過程の解明や他の文献との関係性の可視化に取り組むことができる。Oliverとの研究はさらに次の段階に入り、ベイズ統計モデルによる文献年代推定プログラムの開発というところに来ていて、もちろん私はプログラムの仕組みそのものはわからないのであるが、私が文献をひたすら読んで得てきたもの、語順や構文、代名詞の用法の微妙な違いをAI が学んでくれる ようになるなら、弟子ができるような気持ちにならなくもない。弟子に超えられる(幸せな)気分と人間が人工知能に負ける瞬間を同時に味わうことになるのだろうか。けっこう楽しみである。
2021年2月に開催した国際ワークショップには10 か国から約120名もの参加があった。

人文科学研究所共同研究拠点の国際研究ミーティングとしても助成されたので、インターナショナルな告知に力を入れました!
 >
>
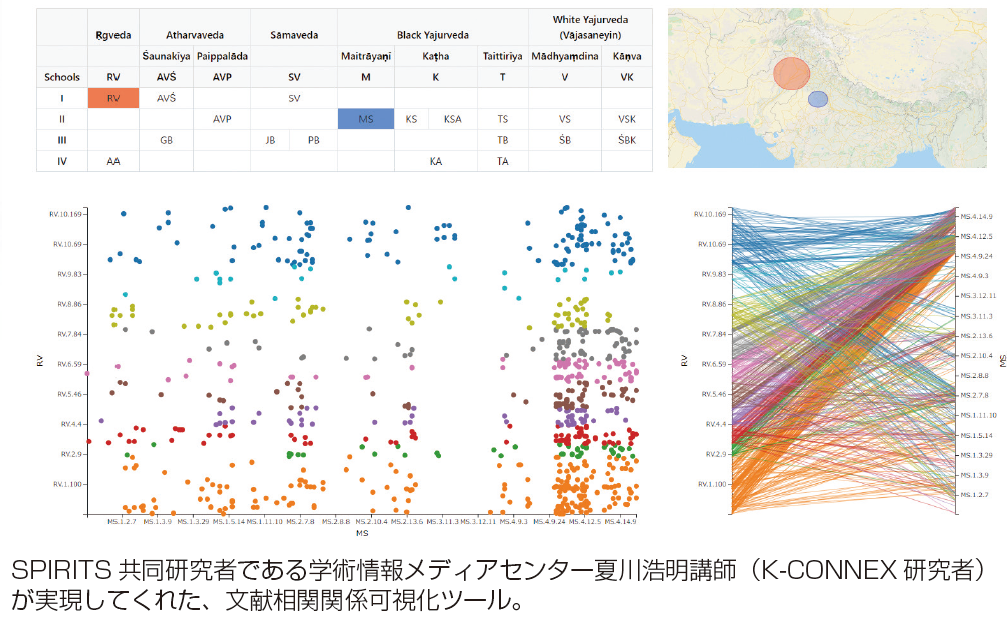
SPIRITS共同研究者である学術情報メディアセンター夏川浩明講師(K-CONNEX研究者)が実現してくれた、文献相関関係可視化ツール。
(あまの きょうこ)








